Co-Author: Eric Kammers
Part 1 – Theoretical Background
The Dynamic Mode Decomposition (DMD) was originally developed for its application in fluid dynamics where it could decompose complex flows into simpler low-rank spatio-temporal features. The power of this method lies in the fact that it does not depend on any principle equations of the dynamic system it is analyzing and is thus equation-free [1]. Also, unlike other low-rank reconstruction algorithms like the Singular Value Decomposition (SVD), the DMD can be used to make short-term future state predictions.
The algorithm is implemented as follows [2].
1. We begin with a 


2. From this matrix two sub-matrices are constructed, 



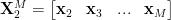
We can consider a Koopman operator 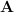
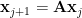

whose columns now are elements in a Krylov space.
3. The SVD decomposition of

Then based on the variance captured by the singular values and the application of the algorithm, the number of desired reconstructions ranks can be chosen.
4. The matrix
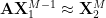


where 
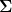

where 

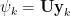
5. The approximated solution for all future times, 

where 


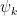


To summarize the algorithm, we will “train” a matrix
Part 2 – Basic Demonstration
We begin with a basic example to demonstrate how to use the pyDMD package. First, we construct a matrix 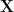

Now we will attempt to predict the predict the 6th row using a future state prediction from the DMD fitted on the first 5 rows.
import numpy as np
from pydmd import DMD
df = np.array([[-2,6,1,1,-1],
[-1,5,1,2,-1],
[0,4,2,1,-1],
[1,3,2,2,-1],
[2,2,3,1,-1],
[3,1,3,2,-1]])
dmd = DMD(svd_rank = 2) # Specify desired truncation
train = df[:5,:]
dmd.fit(train.T) # Fit the model on the first 5 rows
dmd.dmd_time['tend'] *= (1+1/6) # Predict one additional time step
recon = dmd.reconstructed_data.real.T # Make prediction
print('Actual :',df[5,:])
print('Predicted :',recon[5,:])
Two SVD ranks were used for the reconstruction and the result is pleasantly accurate for how easily it was implemented.


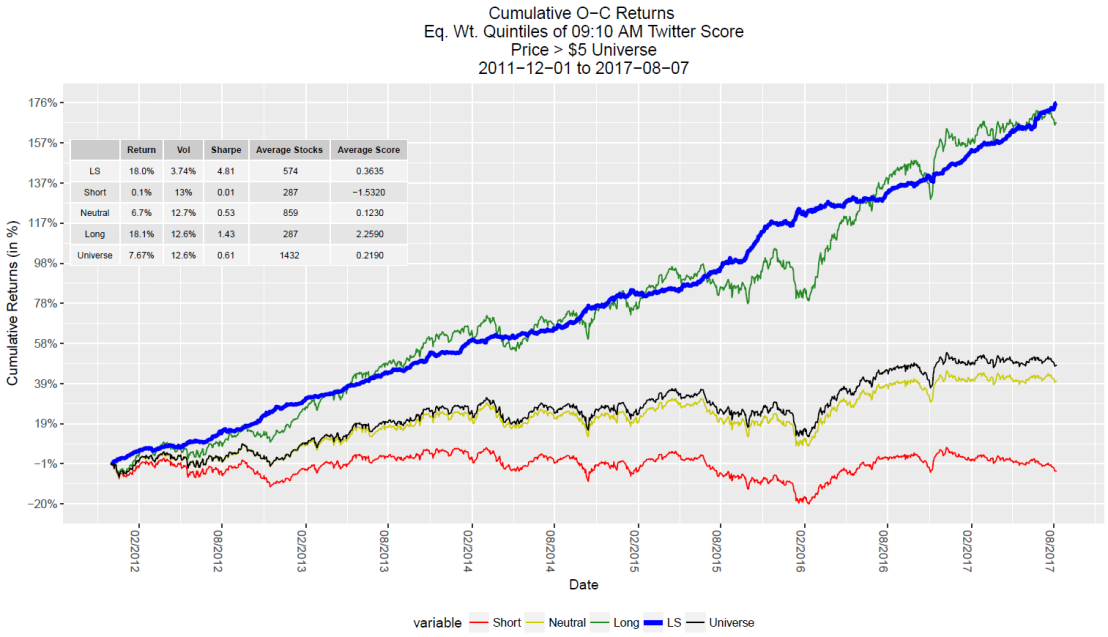
Part 3 – Sector Rotation Strategy
We will now attempt to model the stock market as a dynamic system broken down by sectors and use the DMD to predict which sectors to be long and short in over time. This is commonly known as a sector rotation strategy. To ensure that we have adequate historical data we will use 9 sector ETFs: XLY, XLP, XLE, XLF, XLV, XLI, XLB, XLK, and XLU from 2000-2019 and rebalance monthly. The strategy is implemented as follows:
- Fit a DMD model using the last N months of monthly returns. The SVD rank reconstruction number can be chosen as desired.
- Use the DMD model to predict the next month’s snapshot which are the returns of each ETF.
- Construct the portfolio by taking long positions in the top 5 ETFs and short positions in the bottom 4 ETFs. Thus, we are remaining very close to market neutral.
- Continue this over time by refitting the model monthly and making a new prediction for the next month.
Though the results are quite sensitive to changes in the model parameters, some of the best parameters achieve Sharpe ratios superior to the long only portfolio while remaining roughly market neutral which is very encouraging and warrants further exploration with a proper, robust backtest procedure.

The code and functions used to produce this plot can found here. There are also many additional features of the pyDMD package that we did not explore that could potentially improve the results. If you have any questions, feel free to reach out by email at coltonsmith321@gmail.com
References
[1] N. Kutz, S. Brunton, B. Brunton, and J. Proctor, Dynamic Mode Decomposition: Data-Driven Modeling of Complex Systems. 2016.
[2] Mann, Jordan & Nathan Kutz, J. Dynamic Mode Decomposition for Financial Trading Strategies. Quantitative Finance. 16. 10.1080/14697688.2016.1170194. 2015.