This site will not be updated or monitored going forward.
Category: Quantitative Finance
Risk-Neutral Probability Distributions: CLK2020
Colton Smith & Kevin Schneider
Risk-neutral probability distributions (RND) are used to compute the fair value of an asset as a discounted conditional expectation of its future payoff. In 1978, Breeden and Litzenberger presented a method to derive this distribution for an underlying asset from observable option prices [1]. The derivation of the relationship is well presented in A Simple and Reliable Way to Compute Option-Based Risk-Neutral Distributions by Allan Malz which is summarized below [2].
In the absence of arbitrage, the European call option value can be related to the discounted expected terminal value under the risk-neutral distribution.
![c(t, K, \tau) = e^{-r_t \tau} \tilde{\mathbb{E}}_t\left[\max(S_T - K, 0)\right] = e^{-r_t \tau} \int_K^\infty (s-K) \tilde{\pi}_t(s) ds](https://s0.wp.com/latex.php?latex=c%28t%2C+K%2C+%5Ctau%29+%3D+e%5E%7B-r_t+%5Ctau%7D+%5Ctilde%7B%5Cmathbb%7BE%7D%7D_t%5Cleft%5B%5Cmax%28S_T+-+K%2C+0%29%5Cright%5D+%3D+e%5E%7B-r_t+%5Ctau%7D+%5Cint_K%5E%5Cinfty+%28s-K%29+%5Ctilde%7B%5Cpi%7D_t%28s%29+ds++&bg=FFFFFF&fg=000000&s=1&c=20201002)
where
![\begin{aligned} t &= \text{Time of call option value observation} \\ T &= \text{Expiration} \\ \tau &= \text{Time till expiration in years (} T-t \text{)} \\ K &= \text{Strike price} \\ S_T &= \text{Underlying price at expiration} \\ S_t &= \text{Time-}t \text{ underlying price} \\ r_t &= \text{Time-}t \text{ risk-free interest rate} \\ \tilde{\mathbb{E}}_t[\cdot] &= \text{The expectation from the risk-neutral probability distribution taken at time-}t \\ \tilde{\pi}_t(\cdot) &= \text{The risk-neutral probability density function of }S_T\text{ at time-}t \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+t+%26%3D+%5Ctext%7BTime+of+call+option+value+observation%7D+%5C%5C+T+%26%3D+%5Ctext%7BExpiration%7D+%5C%5C+%5Ctau+%26%3D+%5Ctext%7BTime+till+expiration+in+years+%28%7D+T-t+%5Ctext%7B%29%7D+%5C%5C+K+%26%3D+%5Ctext%7BStrike+price%7D+%5C%5C+S_T+%26%3D+%5Ctext%7BUnderlying+price+at+expiration%7D+%5C%5C+S_t+%26%3D+%5Ctext%7BTime-%7Dt+%5Ctext%7B+underlying+price%7D+%5C%5C+r_t+%26%3D+%5Ctext%7BTime-%7Dt+%5Ctext%7B+risk-free+interest+rate%7D+%5C%5C+%5Ctilde%7B%5Cmathbb%7BE%7D%7D_t%5B%5Ccdot%5D+%26%3D+%5Ctext%7BThe+expectation+from+the+risk-neutral+probability+distribution+taken+at+time-%7Dt+%5C%5C+%5Ctilde%7B%5Cpi%7D_t%28%5Ccdot%29+%26%3D+%5Ctext%7BThe+risk-neutral+probability+density+function+of+%7DS_T%5Ctext%7B+at+time-%7Dt++%5Cend%7Baligned%7D+&bg=FFFFFF&fg=000000&s=1&c=20201002)
Differentiating the call option value with respect to the strike price gives what Malz refers to as the “exercise-price delta”.
![\frac{\partial}{\partial K}c(t, K, \tau) = e^{-r_t \tau}\left[\int_0^K \tilde{\pi}_t(s) ds - 1\right]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+K%7Dc%28t%2C+K%2C+%5Ctau%29+%3D+e%5E%7B-r_t+%5Ctau%7D%5Cleft%5B%5Cint_0%5EK+%5Ctilde%7B%5Cpi%7D_t%28s%29+ds+-+1%5Cright%5D++&bg=FFFFFF&fg=000000&s=1&c=20201002)
This result contains the risk-neutral cumulative distribution function 
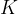

To arrive at the risk-neutral probability density function, one more derivative with respect to the strike price is needed.

Now we will present an overview of deriving these distributions numerically using the infamous May 2020 WTI Crude Oil contract that went negative in April. Albeit these are American options, the analysis is interesting nonetheless.
To approximate the partial derivatives, we need option prices for a fine grid of strike prices. In fact, Breeden and Litzenberger simply assume that options are traded at every positive strike price. The first step is thus to fit a smooth function to the Black-Scholes implied volatility smile of the option prices. We interpolate implied volatilities rather than prices because the former tend to be smoother and better behaved. To ensure that the prices and implied volatilities are clean, open interest can be used to weight or exclude certain strikes. We constructed the smile using out-of-the-money calls and puts as these options tend to have more open interest than their in-the-money equivalents. Numpy’s polyfit is then used to interpolate and extrapolate the smile as needed.

The second step is to calculate the call prices using the Black-Scholes formula for constant rates with your fitted implied volatility function, underlying price, time to expiration, and observed risk-free rate.

The third step, following the mathematical derivation above, is to calculate

To compare these distributions across strike prices, using moneyness, 

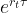

It can be difficult to generate clean RNDs and through this process it became clear how cumbersome it would be to generate these over an extended time series. To evaluate the quality of the fit, we need to check a few conditions.
– The cumulative distribution needs to be bounded between 0 and 1
– The probability density function needs to integrate to 1 and remain positive
– The exercise-price delta needs to be monotone and bounded by 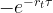
– The strike weighted probability density function needs to integrate to the underlying futures price
There are additional arbitrage conditions to consider on the fitted implied volatility smile but our distributions meet the above conditions nicely so will be sufficient for our analysis. In fact, the absence of arbitrage is one of the few assumptions needed for the above mathematical derivation to hold. Further implicit assumptions include constant interest rates, that the call option price is twice differentiable and that a (smooth) probability density function of the price of the underlying asset exists to start with. Importantly, there are no further restrictions on the probabilistic nature of the underlying asset price process.
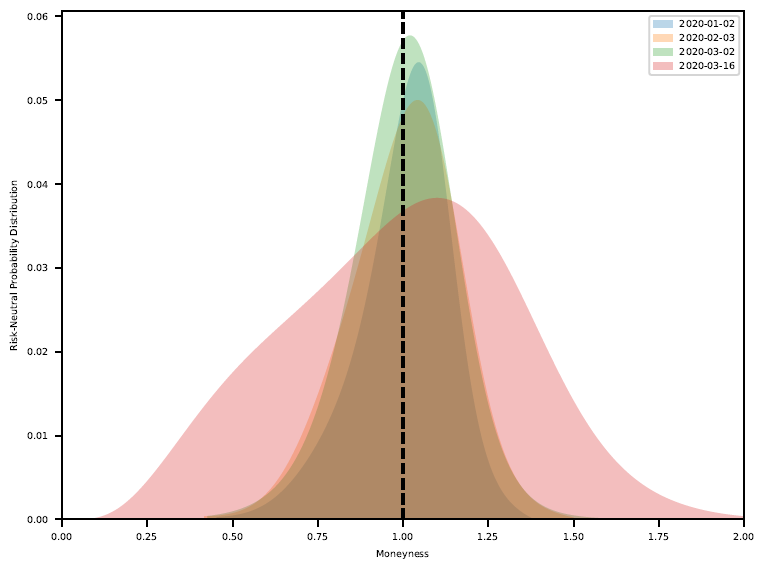
The above technique was repeated on the CLK2020 option chain for the four dates shown in the figure below to see how the option implied volatility RNDs reacted to the developing macro landscape including Covid-19, OPEC+, and crude oil physical storage capacity. The analysis was not extended into April as the possibility of negative prices violate some of the fundamental assumptions used.

The resulting risk-neutral densities below tell quite the colorful story. In January, the distribution has a slight negative skew but high kurtosis. In February and March, the tail risk begins to emerge as the kurtosis decreases. Finally in mid-March the distribution flattens, presenting a very expressive RND.
The corresponding fitted implied volatility smiles are shown below.

At the time, all eyes were on the calendar spreads and bear spreading the futures, short a nearby contract expiration month and long a deferred contact expiration month, was a popular trade. Based on the RND, this trade made sense if you believed that the bulk of the tail risk was in the nearby contract. Using the QuikStrike Commitment of Traders tool on the CME website we can look at the positioning of traders through this event [3]. The plots below show the positioning of the two groups that make up the “Non-Commercial” group of traders which includes hedge funds and large speculators.
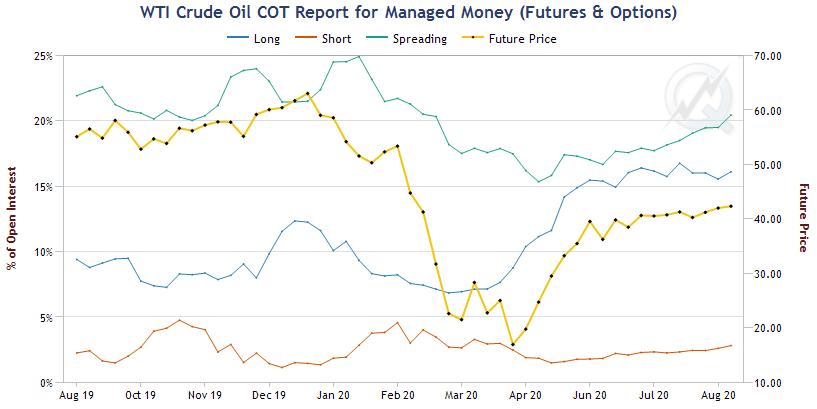

The “Managed Money” began the year with a larger spreading position (likely bear?) which decreased into February as a more concentrated short position grew. In April and May, they capitalized on the series of events, quickly building a fervent long position to ride the rally back up.
The “Other Reportables” held a large spreading positioning from the end of February until May, likely capturing the historical calendar spread move nicely.
It is important to emphasize that risk-neutral distributions are different from the real-world distributions which govern the likelihood of events in financial markets. A RND is an artificial probability distribution which allows the computation of option prices without specifying the risk aversion of investors (this insight is the reason for Scholes’ and Merton’s Nobel Prize in 1997). Thus, they are a very convenient mathematical tool but not a description of the real world.
Intuitively, RNDs merge real-world probabilities with investor’s attitudes toward risk. They tend to inflate the probability of economically bad states (which are rare but investors are very fearful of them) and understate the probability of booms. Hence, RNDs tend to be more negatively skewed than real-world distributions are.
In fact, the above idea can be formulated more rigorously. Let’s use a discrete setting for simplicity. Suppose we want to price an asset which generates a random cash flow of 

![c = \mathbb{E}[XM],](https://s0.wp.com/latex.php?latex=c+%3D+%5Cmathbb%7BE%7D%5BXM%5D%2C++&bg=FFFFFF&fg=000000&s=1&c=20201002)
where the random variable 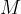
![\begin{aligned} c&=\sum_i x_i M_i p_i \\ &= \frac{1}{1+r} \sum_i x_iq_i \\ &= \frac{1}{1+r} \tilde{E}[X], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+c%26%3D%5Csum_i+x_i+M_i+p_i+%5C%5C+%26%3D+%5Cfrac%7B1%7D%7B1%2Br%7D+%5Csum_i+x_iq_i+%5C%5C+%26%3D+%5Cfrac%7B1%7D%7B1%2Br%7D+%5Ctilde%7BE%7D%5BX%5D%2C+%5Cend%7Baligned%7D++&bg=FFFFFF&fg=000000&s=1&c=20201002)
where 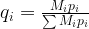
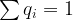
![q_i\in[0,1]](https://s0.wp.com/latex.php?latex=q_i%5Cin%5B0%2C1%5D+&bg=FFFFFF&fg=000000&s=1&c=20201002)

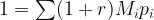

This short derivation illustrates how merging the risk aversion (in form of 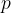

Changes in the RND can be attributed to changes in investor’s preferences, real-world probabilities, or both. A priori, it is impossible to know which of the three cases is true. Disentangling real-world probabilities from risk aversion typically requires a general equilibrium model of the economy and remains an open question for current research, see Ross (2015) [4] for a recent attempt.
References
[1] https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2642349
[2] https://www.newyorkfed.org/medialibrary/media/research/staff_reports/sr677.pdf
[3] https://www.cmegroup.com/tools-information/quikstrike/commitment-of-traders-energy.html
[4] https://onlinelibrary.wiley.com/doi/abs/10.1111/jofi.12092
Combinatorial Purged Cross-Validation Explained
In this tutorial I explain how to adapt the traditional k-fold CV to financial applications with purging, embargoing, and combinatorial backtest paths.
Building a Basic Cross-Sectional Momentum Strategy – Python Tutorial
In this tutorial we utilize the free Alpha Vantage API to pull price data and build a basic momentum strategy that is rebalanced weekly. This approach can be adapted for any feature you’d like to explore. Let me know what you’d like to see in the next video!
